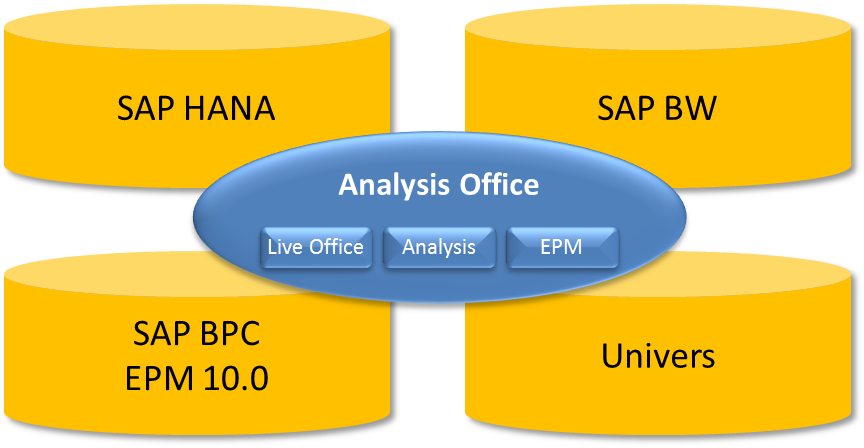
L’une des vocations de la business intelligence est de permettre des analyses dynamiques sur des informations provenant de multiples sources de données, sans distinction de leur origine.
SAP HANA propose déja de stocker des données provenant de plusieurs sources (répliquées de l’ERP avec un SLT, par exemple, ou directement enregistrées dans la base par les applications) ou virtualisées avec un accès distant en temps réel. Toutes ces données sont alors accessibles, via des Analytics Views, dans les providers de SAP BW ou directement par les outils de restitution tels que Lumira, Analysis Office ou Design Studio.
SAP HANA VORA, qui est en disponibilité générale depuis mars 2016, permet d’effectuer ces analyses en donnant accès aux données « Big Data » de Hadoop. En résumé, rappelons que Hadoop est un framework open source basé sur Apache, devenu incontournable dès lors qu’il s’agit d’une problématique de stockage de larges volumes de données. Apache Spark, qui travaille en mémoire, permet de lancer des analyses de type SQL sur les données Hadoop.
SAP HANA VORA n’entre pas en concurrence avec Hadoop et Spark mais vient en étendre les capacités. Il s’agit principalement de deux composants (Vora Spark Extension library et Vora SQL Engine) qui s’installent sur le serveur Apache. Ils offrent la possibilité d’effectuer des requêtes s’appuyant sur des hiérarchies et rendent possibles les analyses de type OLAP.
On peut également utiliser SAP HANA VORA en stand alone, sans connexion avec SAP HANA, mais l’idée selon moi est plutôt de bénéficier des possibilités de VORA et Hadoop dans un environnement où SAP HANA centralise tous les accès aux données.
Désormais, on peut disposer des tables VORA virtualisées dans HANA pour les employer dans des HANA Views, comme n’importe quelle autre table, ou même se connecter directement à VORA dans Lumira grâce au connecteur générique JDBC (classe « com.simba.spark.jdbc4.Driver »).
La capacité d’analyse décisionnelle sur des données Hadoop laisse entrevoir de très nombreux usages (marketing, production, etc) en particulier à l’heure des IoT et du temps réel sur des données de masse. Il reste à évaluer les conséquences en matière de temps de réponse pour les utilisateurs, car un manque de performance amènerait à reconsidérer la pertinence d’une pré-agrégation de données à des fins d’analyse que le in-memory avait rendu obsolète. Dans tous les cas une stratégie sur le choix de stockage des données à haute valeur ou à faible valeur, entre Hana, Hadoop et autres bases, doit être mise sur pied en fonction des besoins d’analyse et de conservation de données.